![[SQL] Join 종류 간단 정리 + 쿼리 플래닝과 최적화에 대한 개괄(SQLite 기반)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FyjjxJ%2Fbtsm8QIf08M%2FAAAAAAAAAAAAAAAAAAAAAFz7PLECWEpjTzp_fmTE68ShZWMOfyXehUdVDO9hvQ1O%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1777561199%26allow_ip%3D%26allow_referer%3D%26signature%3Dd9B9naEHfuEhbBDchz4SAnVoynw%253D)
/* 칸 아카데미의 SQL 강의를 학습하고 정리한 내용입니다.
*/
여러 Join들
Inner Join
: 양 테이블에 on 컬럼에 해당하는 중복 데이터가 모두 존재할 때만 join해줌.
ex) students 테이블과 student_projects 테이블이 각각 이렇게 생겼을 때:
students(왼 테이블)
| id | first_name | last_name | phone | birthdate | |
| 1 | Peter | Rabbit | peter@rabbit.com | 555-6666 | 2002-06-24 |
| 2 | Alice | Wonderland | alice@wonderland.com | 555-4444 | 2002-07-04 |
student_projects(오른 테이블)
| id | student_id | title |
| 1 | 1 | Carrotapault |
| 2 | 1 | Veggibard |
두 테이블을 학생 id로 inner join 하면:
| id | first_name | last_name | title |
| 1 | Peter | Rabbit | Carrotapault |
| 1 | Peter | Rabbit | Veggibard |
⇒ 두 테이블 모두에 존재하는 학생 id 1번에 대한 결과만 나온다.
SELECT students.id, students.first_name, students.last_name, student_projects.title
FROM students
JOIN student_projects
ON students.id = student_projects.student_idLeft (Outer) Join
: 왼 테이블에 있는 모든 컬럼을 보존하여 join 한다. 만약 오른 테이블에 해당 데이터가 없다면 결과값을 Null로 채운다.
SELECT students.id, students.first_name, students.last_name, student_projects.title
FROM students
LEFT OUTER JOIN student_projects
ON students.id = student_projects.student_id| id | first_name | last_name | title |
| 1 | Peter | Rabbit | Carrotapault |
| 1 | Peter | Rabbit | Veggibard |
| 2 | Alice | Wonderland | NULL |
그 밖에
Right (Outer) Join
Full (Outer) Join
Cross Join
Hash Join?
등이 있지만 칸아카데미 에디터에서는 지원하지 않으므로 생략한다.
연습문제:
- 고객 리스트와 구매 리스트가 있을 때, 구매하지 않은 고객도 포함하여 모든 고객의 구매 기록(이름, email, 구매상품, 가격)을 볼 수 있는 쿼리:
SELECT c.name, c.email, o.item, o.price FROM customers AS c LEFT JOIN orders AS o ON c.id = o.customer_id;name email item price Doctor Who doctorwho@timelords.com Sonic Screwdriver 1000 Doctor Who doctorwho@timelords.com TARDIS 1000000 Harry Potter harry@potter.com High Quality Broomstick 40 Captain Awesome captain@awesome.com NULL NULL
- 위와 같은 테이블에서 고객당 총 구매 가격(이름, email, 총 가격)을 가장 많은 돈을 쓴 고객 순으로 나열하는 쿼리(구매 기록이 없는 고객도 포함):
SELECT c.name, c.email, SUM(o.price) AS total_spent FROM customers AS c LEFT JOIN orders AS o ON c.id = o.customer_id GROUP BY c.id ORDER BY price DESC;name email total_spent Doctor Who doctorwho@timelords.com 1001000 Harry Potter harry@potter.com 40 Captain Awesome captain@awesome.com NULL
- 고객 리스트와 구매 리스트가 있을 때, 구매하지 않은 고객도 포함하여 모든 고객의 구매 기록(이름, email, 구매상품, 가격)을 볼 수 있는 쿼리:
Self Join
: 자기 자신 테이블과 join할 수도 있다. 이 때 테이블명이 겹치게 되므로 반드시 alias를 (최소) 한 쪽에 걸어주어야 한다.
Students
| id | first_name | last_name | phone | birthdate | buddy_id | |
| 1 | Peter | Rabbit | peter@rabbit.com | 555-6666 | 2002-06-24 | 2 |
| 2 | Alice | Wonderland | alice@wonderland.com | 555-4444 | 2002-07-04 | 1 |
| 3 | Aladdin | Lampland | aladdin@lampland.com | 555-3333 | 2001-05-10 | 4 |
| 4 | Simba | Kingston | simba@kingston.com | 555-1111 | 2001-12-24 | 3 |
buddy_id를 기반으로 학생 각각의 이름과 친구 email을 출력하고 싶을 때:
SELECT students.first_name, students.last_name, buddies.email as buddy_email
FROM students
JOIN students buddies
ON students.buddy_id = buddies.id;| first_name | last_name | buddy_email |
| Peter | Rabbit | alice@wonderland.com |
| Alice | Wonderland | peter@rabbit.com |
| Aladdin | Lampland | simba@kingston.com |
| Simba | Kingston | aladdin@lampland.com |
연습문제2:
- Inner join과 self join 합성:
다음과 같은 테이블들이 있을 때, 결과 테이블을 만드는 쿼리는?
students: 학생 명부
id first_name last_name email phone birthdate 1 Peter Rabbit peter@rabbit.com 555-6666 2002-06-24 2 Alice Wonderland alice@wonderland.com 555-4444 2002-07-04 3 Aladdin Lampland aladdin@lampland.com 555-3333 2001-05-10 4 Simba Kingston simba@kingston.com 555-1111 2001-12-24 student_projects: 학생 개인의 프로젝트명
id student_id title 1 1 Carrotapault 2 2 Mad Hattery 3 3 Carpet Physics 4 4 Hyena Habitats projects_pairs: 서로의 프로젝트를 리뷰할 짝(그룹)
id project1_id project2_id 1 1 2 2 3 4 원하는 결과 테이블: projects_pairs에서 프로젝트 id 대신 프로젝트명으로 보고 싶다.
pair_id title title 1 Carrotapault Mad Hattery 2 Carpet Physics Hyena Habitats ⇒
SELECT p.id AS pair_id, a.title, b.title FROM project_pairs p JOIN student_projects a ON p.project1_id = a.id JOIN student_projects b ON p.project2_id = b.id;
- 위의 조건에서, pairs의 프로젝트’명’ 뿐만 아니라 해당하는 학생 이름도 같이 보고 싶다:
pair_id project1 student1 project2 student2 1 Carrotapault Rabbit Mad Hattery Wonderland 2 Carpet Physics Lampland Hyena Habitats Kingston ⇒
SELECT p.id AS pair_id, a.title AS project1, s1.last_name AS student1, b.title AS project2, s2.last_name AS student2 FROM project_pairs p JOIN student_projects a ON p.project1_id = a.id JOIN student_projects b ON p.project2_id = b.id JOIN students s1 ON a.student_id = s1.id JOIN students s2 ON b.student_id = s2.id;
- Inner join과 self join 합성:
쿼리 플래닝과 최적화로 SQL 더 효율적으로 이용하기
SQL은 declarative language라서, 각각의 쿼리는 SQL 엔진이 ‘무엇을’ 하는가만 정의하지 그것을 어떻게 수행하는지는 정해주지 않는다. 사실 이 ‘어떻게(plan)’ 파트가 바로 쿼리의 효율성을 결정짓는 요소인데 말이다. 그래서 각 SQL 엔진이 이 ‘어떻게’를 내부적으로 어떻게 처리하느냐로 성능이 갈린다.
SQL 쿼리문은 왜 plan이 필요한가
SELECT * FROM books WHERE author = "J K Rowling";이같은 간단한 쿼리문이 있다고 할 때, SQL이 결과를 가져오는 방법엔 2가지가 있을 수 있다:
- 전체 테이블을 처음부터 하나하나 대조하여 조건에 맞는 행을 반환한다.
- 정렬된 author 컬럼 복사본을 만들어서 저자가 J K Rowling인 행을 이진 탐색으로 찾는다. 찾은 행들의 id를 기억했다가, 원본 테이블에서 해당하는 id들을 또다시 이진 탐색으로 찾아서 full 행을 반환한다.
뭐가 더 빠른지는 데이터의 양과 쿼리문이 얼마나 자주 실행될 것인가에 따라 다르다. 만약 테이블이 10줄밖에 안된다면 full table scan이 더 빠를 것이다. 그런데 1000만 줄쯤 되면 인덱스를 이진 탐색하는 방법이 더 빠를 수 있다. 1000만 줄을 이진 탐색하려면 23번만 검색하면 되는데, 처음에 그 ‘정렬된 테이블(인덱스)’을 만드는데 대략 2억 3000만 번의 실행(테이블 전체 길이의 23배)이 필요하다는 단점이 있다. 그래서 데이터의 양과 실행 빈도가 중요한 것이다. 만약 이미 만들어진 인덱스가 있거나(처음의 2억 3000만 실행을 생략할 수 있으므로), 같은 쿼리문을 23번 이상(full scan의 1000만 실행을 23번 하는 것 이상) 부르게 될 거라면 익덱스를 활용하는 2번째 플랜이 더 효과적일 것이다.
어쨌든 이러한 이유로 SQL 엔진이 어떤 ‘플랜’을 선택할 것인지를 결정하게 하는 방법이 중요하다.
SQL 쿼리의 생애
한 번의 쿼리문마다 SQL 엔진은 다음과 같은 단계를 밟는다:
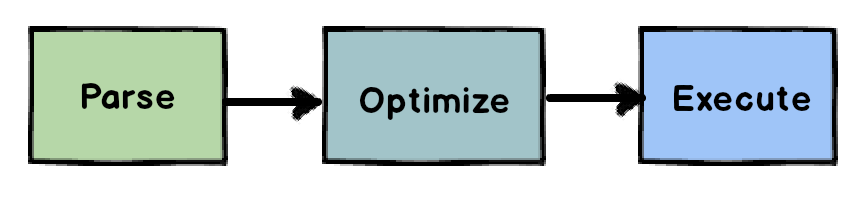
- Query parser가 문법(syntatically)과 의미상(semantically)으로 알맞은지를 체크한다. 실패하면 에러를 내고, 성공이면 숫자로 된 표현식을 만들어 다음 단계로 넘긴다.
- syntatical(문법) 에러 ex) 콤마가 알맞지 않은 곳에 찍힘
- semantic(의미상) 에러 ex) 해당 테이블이 존재하지 않음
- Query planner와 Optimizer가 핵심 로직을 담당한다. 먼저 간단한 사전 최적화(straightforward optimizations)를 실행해 실행 문구를 줄인다. 다음으로 연관된 테이블들의 행 수에 기반하여 다양한 “qeury plan”들에 소요될 CPU와 시간을 계산하고, 이를 바탕으로 가장 비용이 적은 plan을 선택해 다음 단계로 넘긴다.
- Query executor가 마침내 해당 시나리오(plan)대로 데이터베이스에 실행하고, 반환값이 있다면 반환해준다.
사람이 끼어들 구석은?
쿼리 플래닝과 최적화는 쿼리문이 실행될 때마다 매번 수행된다. 다루는 데이터베이스가 커질수록 쿼리 수행 속도를 어떻게 올릴지가 중요한 문제가 되기 마련인데, SQL 엔진이 자동으로 하는 플래닝과 최적화 외에도 프로그래머가 직접적으로 도움을 줄 수 있는 부분이 있다. 이를 쿼리 튜닝(query tuning)이라고 한다.
- 첫 번째 단계는 어디에 튜닝이 필요한지 파악하는 것이다. SQL 프로파일러 같은 도구로 어느 데이터베이스에서 과도한 시간이나 CPU를 사용하는지, 그래서 어느 쿼리를 손봐야 하는지를 파악한다.
- 다음 단계는 내가 사용하는 SQL 엔진이 어떻게 쿼리를 실행하고 있는지를 이해하는 것이다. SQL 시스템마다 플랜을 보여달라는 문법이 존재한다. 예를 들어 SQLite은 “
EXPLAIN QUERY PLAN”을 쿼리문 앞에 붙이면 된다(결과로 나오는 데이터 해석은 EXPLAIN QUERY PLAN reference를 깊이 탐독해야 할 것이다). 다른 엔진을 사용하고 있다면 “how do i get an execution plan in X”같은 키워드로 검색해볼 수 있다.
- 그렇게 파악한 execution plan을 직접 조율해준다. 어떤 SQL 엔진을 쓰느냐와 어떤 데이터를 다루고 있느냐에 따라 세밀하게 달라진다. 예를 들어, 처음 예제에서 ‘저자 컬럼을
WHERE로 조건 짓는 쿼리를 수백번 실행시킬 예정’임을 사전에 알았다면 먼저CREATE INDEX문법으로 저자 컬럼 인덱스를 미리 만들어놓는 것으로 튜닝을 가해줄 수 있을 것이다. 그러면 SQL 엔진의 플랜 계산 과정에서 이 인덱스가 사용되어 더 빠른 최적 플랜(앞서 살펴본 2번, 인덱스 시나리오에서 인덱스를 만드는 첫 2억 3000만 실행이 (감개무량하게도) 생략된)이 실행된다.
- 인덱스를 적절히 추가해주는 것 외에도 SQLite의 쿼리를 튜닝하는 방법은 다음 문서 중 “manual” 파트를 읽어보자: The SQLite Query Optimizer Overview
https://www.sqlite.org/optoverview.html
⇒ 내용 소개: 어떤 쿼리문의 한 plan을 어떻게 ‘더 효율적으로’ 만드는가.
- 인덱싱이 언제 쓸모있게 되는지에 대해선 다음 문서를 추가로 읽어보자: Query Planning
⇒ 내용 소개: 비하인드 씬을 통째로 담당한다고 할 수 있는 query planner AI가 어떻게 최적의 실행 알고리즘을 선택하는가에 대한 설명. 인덱스가 있을 때와 없을 때, 여러 WHERE 절이 묶였을 때 등등의 다양한 조건의 쿼리문에서 어떤 논리로 결과값을 찾아내는가를 설명하고 있으며, 이렇게 각각의 조건에서 수행되는 작업 개수를 이해함으로써 query planner AI가 판단할 ‘최적 알고리즘(plan)’이 어느 것일지 이해할 수 있다.
Uploaded by N2T